Dynamic Routing Between Capsules
Convolutional neural networks have dominated the computer vision landscape ever since AlexNet won the ImageNet challenge in 2012, and for good reason. Convolutions create a spatial dependency inside the network that functions as an effective prior for image classification and segmentation. Weight sharing reduces the number of parameters, and efficient accelerated implementations are readily available. These days, convolutional neural networks (or “convnets” for short) are the de facto architecture for almost any computer vision task.
However, despite the enormous success of convnets in recent years, the question begs to be asked, “Can we do better?” Are there underlying assumptions built into the fundamentals of convnets that makes them in some ways deficient?
Capsule networks are novel one architecture that attempts to supersede traditional convnets. Geoffrey Hinton, who helped develop the backpropagation algorithm and has pioneered neural networks and deep learning, has talked about capsule networks for some time, but until very recently no work on the idea had been publicly published. Just a few weeks ago, Dynamic Routing Between Capsules by Sara Sabour, Nicholas Frosst and Geoffrey Hinton was made available, explaining what capsule networks are and the details of their functionality. Here, I’ll walk through the paper and give a high level review as to how capsules function, the routing algorithm described in the paper, and the results of using a capsule network for image classification and segmentation.
Why Typical Convnets are Doomed
Before we dive into how capsules solve the problems of convnets, we first need to establish what capsules are trying to solve. After all, modern convnets can be trained for near-perfect accuracy over a million images with a thousand classes, so how bad can they be? While traditional convnets are great at classifying images like ImageNet, they fall short of perfect in some key ways.
Sub-sampling loses precise spatial relationships
Convolutions are great because they create a spatial dependency in our models (see my previous post for a high level overview of convolutions, or these lecture notes for an in-depth explanation of convnets), but they have a key failure. Commonly, a convolutional layer is followed by a (max) pooling layer. The pooling layer sub-samples the extracted features by sliding over patches and pulling out the maximum or average value. This has the benefit of reducing the dimensionality (making it easier for other parts of our network to work with), but also loses precise spatial relationships.
By precise spatial relationships, I mean the exact ways that the extracted features relate to one another. For instance, consider the following image of a kitten:

A pretrained ResNet50 convnet classifies as a tabby cat, which is obviously correct. Convnets are excellent at detecting specific features within an image, such as the cats ears, nose, eyes, paws, etc. and combining them to form a classification. However, sub-sampling via pooling loses the exact relationship that those features share with each other: e.g. the eyes should be level and the mouth should be underneath them. Consider what happens when I edit some of the spatial relationships, and create a kitten image more in the style of Pablo Picasso:

When this image is fed to our convnet, we still get a tabby classification with similar confidence. That’s completely incorrect! Any person can immediately tell by looking at the image something isn’t right, but the convnet plugs along as if the two images are almost identical.
Convnets are invariant, not equivariant
Another shortcoming of typical convnets is that the explicitly strive to be invariant to change. By invariant, I mean that the entire classification procedure (the hidden layer activations and the final prediction) are nearly identical to small changes in the input (such as shift, tilt, zoom). This is effective for the classification task, but it ultimately limits our convents. Consider what happens when I flip the previous image of the kitten upside-down:

This time, our ResNet thinks our kitten is a guinea pig! The problem is that while convnets are invariant to small changes, they don’t react well to large changes. Even though all the features are still in the image, the lack of spatial knowledge within the convnet means it can’t make head or tail of such a transformation.
Rather than invariance that’s built into traditional convnets by design in pooling layers, what we should really strive for is equivariance: the model will still produce a similar classification, but the internal activations transform along with the image transformations. Instead of ignoring transformations, we should adjust alongside them.
A note on sub-sampling
Before we proceed, I feel it necessary to point out that Hinton identifies these problems with sub-sampling in convnets, not the convolution operation itself. The sub-sampling in typical convnets (usually max-pooling) is largely to blame for these deficiencies in convnets. The convolution operation itself is quite useful, and is even utilized in the capsule networks presented.
Capsules to the Rescue
These kinds of problems (lack of precise spatial knowledge and invariance to transformations) are exactly what capsules try to solve. Most simply, a capsule is just a group of neurons. A typical neural network layer has some number of neurons, each of which is a floating point number. A capsule layer, on the other hand, is a layer that has some number of capsules, each of which is a grouping of floating point neurons. In this work, a capsule is a single vector, though later work utilizes matrices for their capsules.
The key idea is that by grouping neurons into capsules, we can encode more information about the entity (i.e. feature or object) that we’re detecting. This extra information could be size, shape, position, or a host of other things. The framework of capsules leaves this open, and its up to the implementation to define and enforce these encoding principles.
There’s a few things we need to be careful about before we can get started using capsules. First, since capsules contain extra information, we need to be a little more nuanced about how we connect capsule layers and utilize them in our network. Typical convnets only care about the existence of a feature/object, so their layers can be fully connected without problem, but we don’t get that luxury when we start encoding extra properties with capsules. We also have to be smart about how we connect capsules so that we can appropriately manage the dimensionality without having to resort to pooling.
Connecting Capsule Layers: Dynamic Routing by Agreement
The central algorithm presented in the capsules paper that came out recently is one that describes how capsule layers can be connected to one another. The authors chose an algorithm that encourages “routing by agreement”: capsules in an earlier layer that cause a greater output in the subsequent layer should be encouraged to send a greater portion of their output to that capsule in the subsequent layer.
The routing procedure happens for every forward pass through the network, both during testing and training. The image below visually describes the effect of the routing procedure.
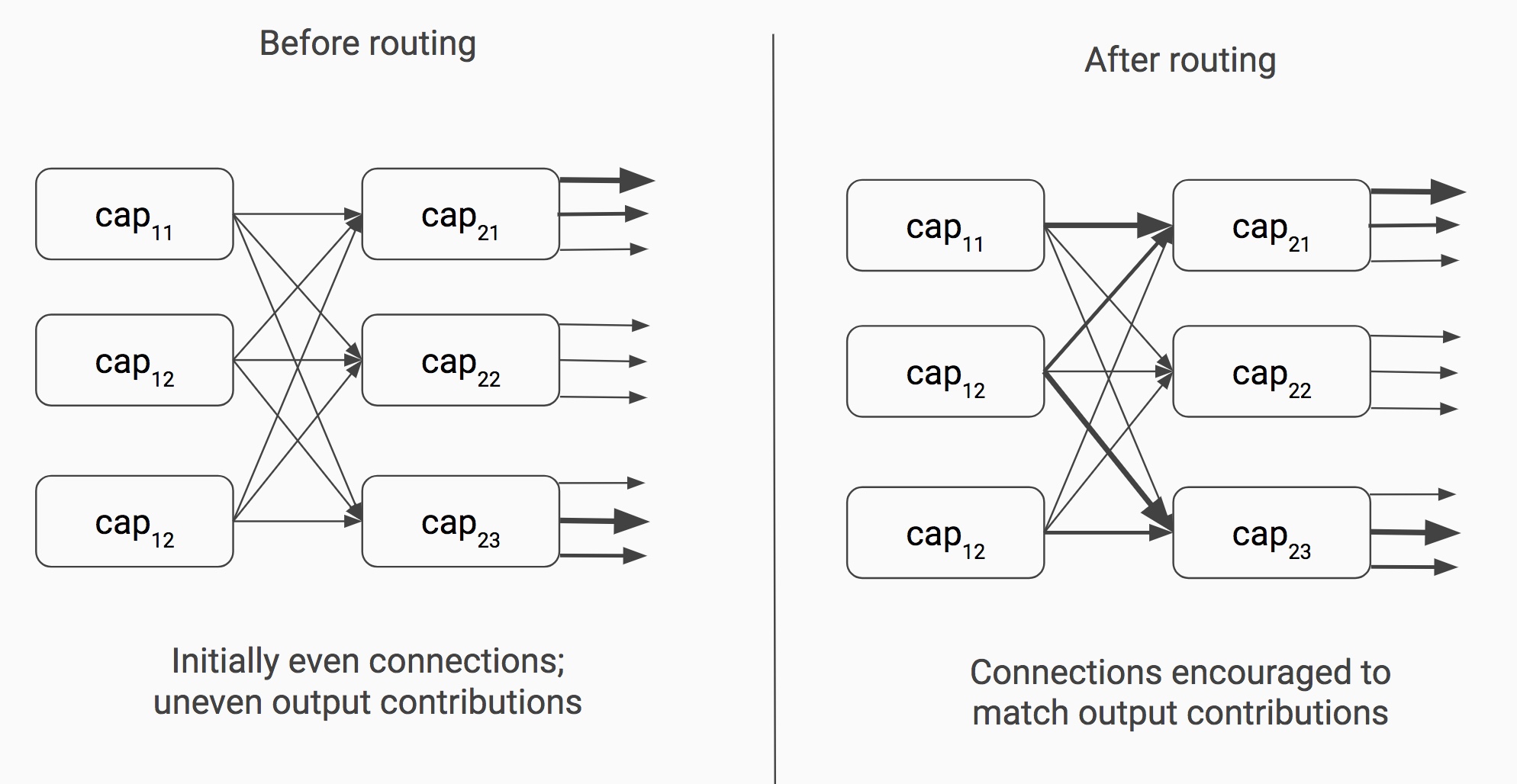
Before the routing procedure, every capsule in the earlier layer spreads its
output evenly to every capsule in the subsequent layer (initial couplings can
be learned like weights, but this isn’t done in the paper). During each
iteration of the dynamic routing algorithm, strong outputs from capsules in the
subsequent layer are used to encourage capsules in the previous layer to send a
greater portion of their output. Note how caps_21 has a large portion of its
output influenced by caps_11 (denoted by the thick arrow coming out on top).
After the routing procedure, caps_11 sends much more of its output toward
caps_21 than any of the other capsules in the second layer.
The mathematical details of this procedure are excellently explained in the original paper, but for brevity I will omit a complete explanation.
CapsNet: A Shallow Network with Deep Results
Now let’s look at the actual capsule network utilized int the paper, known as CapsNet.
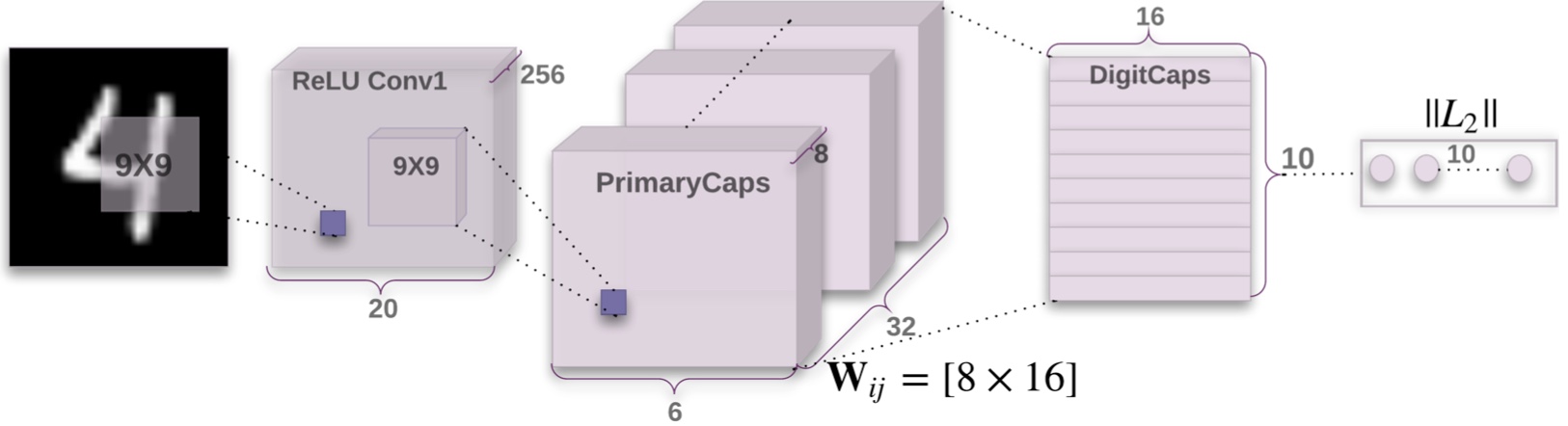
Our input images are the MNIST data set: 28x28 grayscale pictures of handwritten digits (later we’ll see how capsules perform on other, more complex data sets). These get fed into a convolutional layer (256 9x9 filters, stride of 1 and no padding). That layer passes through another set of convolutions to become the PrimaryCaps layer, the first capsule layer. Each capsule inside PrimaryCaps is a size 8 vector. There are 32x6x6 = 1152 of the capsule in the PrimaryCaps layer. In the paper, they construct their capsule architecture such that the length of a capsule (i.e. the value after putting the vector through the Euclidean norm) represents the likelihood an entity exists, and the orientation (i.e. how the values are distributed within a capsule) represents all other spatial properties of the entity.
The PrimaryCaps layer is connected to the DigitCaps layer. This is the only place in the CapsNet architecture where routing takes place. DigitCaps is a layer of 10 capsules (one corresponding to each potential digit), each a size 16 vector. Since the length of the vector corresponds to its existence, all we need to do is norm the capsules in DigitCaps to get our logits, which can be fed into a softmax layer to get prediction probabilities.
Since each digit could appear independently, and in some tests multiple digits, the authors used a custom loss function that penalized each digit independently during training. Additionally, they wanted to ensure that each DigitCaps was learning a good representation within the capsule. To do this they appended a fully connected network to function as a decoder and attempt to reconstruct the original input from the DigitCaps layer.
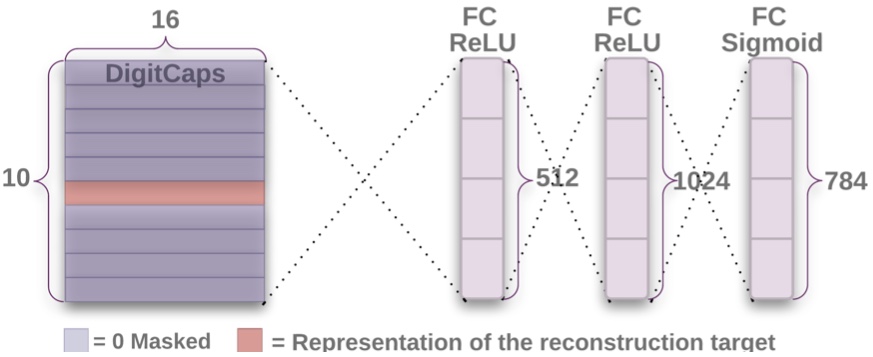
Only the capsule value from the correct label was used to reconstruct (the others were masked out). The reconstruction error was used to regularize CapsNet during training, forcing the DigitCaps layer to learn more about how the digit appeared in the image.
Results
With only three layers, the CapsNet architecture performed remarkably well. The authors report a 0.25% test error rate on MNIST, which is close to state of the art and not possible with a similarly shallow convnet.
They also performed so experiments on a MultiMNIST data set: two images from MNIST overlapping each other by up to 80%. Since CapsNet understands more about size, shape, and position, it should be able to use that knowledge to untangle the overlapping words.

The image above represents CapsNet reconstructing its predictions twice, one for each digit in the image. The red corresponds to one digit, and green for another (yellow is where they overlap). CapsNet is extremely good at this kind of segmentation task, and the authors suggest is in part because the routing mechanism serves as a form of attention.
CapsNet is also performant on several other data sets. On CIFAR-10, it has a 10.6% error rate (with an ensemble and some minor architecture modifications), which is roughly the same as when convnets were first used on the data set. CapsNet attain 2.7% error on the smallNORB data set, and 4.3% error on a subset of Street View Housing Numbers (SVHN).
Conclusion
Convnets are extremely performant architectures for computer vision tasks. Their resurgence has marked the recent AI renaissance currently unfolding with the advent of deep learning. However, they suffer from some serious flaws that make them unlikely to take us all the way to general intelligence.
Capsules are a novel enhancement that go beyond typical convnets by encoding extra information about detected objects and retain precise spatial relationships by avoiding sub-sampling. The simple capsule architecture presented in this paper, CapsNet, is able to get incredible results considering its small size. Additionally, CapsNet understands more about the images its classifying, like their position and size.
Although CapsNet doesn’t necessarily outperform convnets, they are able to match their accuracy out-of-the-box. This is really promising for the future role of capsules in computer vision. There’s still a huge amount to research to be done into improving capsules and scaling them to larger data sets. As a computer vision researcher, this is an extremely exciting time to be working in the field!